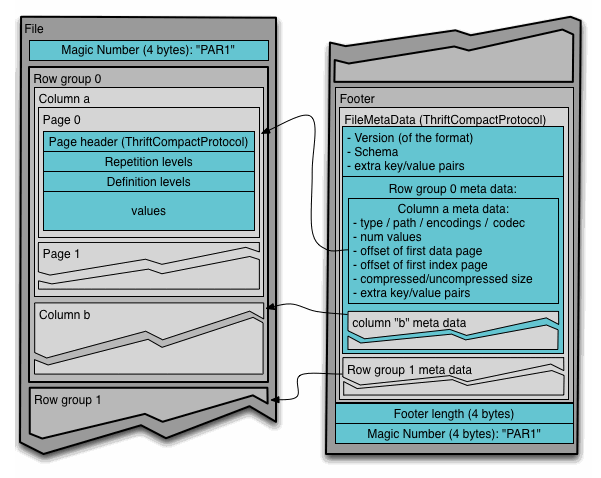
File Format
Documentation about the Parquet File Format.
This file and the thrift definition should be read together to understand the format.
4-byte magic number "PAR1"
<Column 1 Chunk 1>
<Column 2 Chunk 1>
...
<Column N Chunk 1>
<Column 1 Chunk 2>
<Column 2 Chunk 2>
...
<Column N Chunk 2>
...
<Column 1 Chunk M>
<Column 2 Chunk M>
...
<Column N Chunk M>
File Metadata
4-byte length in bytes of file metadata (little endian)
4-byte magic number "PAR1"
In the above example, there are N columns in this table, split into M row groups. The file metadata contains the locations of all the column chunk start locations. More details on what is contained in the metadata can be found in the Thrift definition.
File metadata is written after the data to allow for single pass writing.
Readers are expected to first read the file metadata to find all the column chunks they are interested in. The columns chunks should then be read sequentially.
The format is explicitly designed to separate the metadata from the data. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files.